Overview¶
Developer Note: if you may make a PR in the future, be sure to copy this
notebook, and use the gitignore prefix temp to avoid future conflicts.
This is one notebook in a multi-part series on Spyglass.
- To set up your Spyglass environment and database, see the Setup notebook
- For additional info on DataJoint syntax, including table definitions and inserts, see the Insert Data notebook
Extract the recording
- Specifying your NWB file.
- Specifying which electrodes involved in the recording to sort data from. -
SortGroup - Specifying the time segment of the recording we want to sort. -
IntervalList,SortInterval - Specifying the parameters to use for filtering the recording. -
SpikeSortingPreprocessingParameters - Combining these parameters. -
SpikeSortingRecordingSelection - Extracting the recording. -
SpikeSortingRecording - Specifying the parameters to apply for artifact detection/removal. -
ArtifactDetectionParameters
Spike sorting the recording
- Specify the spike sorter and parameters to use. -
SpikeSorterParameters - Combine these parameters. -
SpikeSortingSelection - Spike sort the extracted recording according to chose parameter set. -
SpikeSorting
Imports¶
Let's start by importing tables from Spyglass and quieting warnings caused by some dependencies.
Note: It the imports below throw a FileNotFoundError, make a cell with !env | grep X where X is part of the problematic directory. This will show the variable causing issues. Make another cell that sets this variable elsewhere with %env VAR="/your/path/"
import os
import datajoint as dj
import numpy as np
# change to the upper level folder to detect dj_local_conf.json
if os.path.basename(os.getcwd()) == "notebooks":
os.chdir("..")
dj.config.load("dj_local_conf.json") # load config for database connection info
import spyglass.common as sgc
import spyglass.spikesorting.v0 as sgs
from spyglass.spikesorting.spikesorting_merge import SpikeSortingOutput
# ignore datajoint+jupyter async warnings
import warnings
warnings.simplefilter("ignore", category=DeprecationWarning)
warnings.simplefilter("ignore", category=ResourceWarning)
Fetch Exercise¶
If you haven't already done so, add yourself to LabTeam
# Full name, Google email address, DataJoint username, admin
name, email, dj_user, admin = (
"Firstname_spikesv0 Lastname_spikesv0",
"example_spikesv0@gmail.com",
dj.config["database.user"], # use the same username as the database
0,
)
sgc.LabMember.insert_from_name(name)
sgc.LabMember.LabMemberInfo.insert1(
[
name,
email,
dj_user,
admin,
],
skip_duplicates=True,
)
# Make a lab team if doesn't already exist, otherwise insert yourself into team
team_name = "My Team"
if not sgc.LabTeam() & {"team_name": team_name}:
sgc.LabTeam().create_new_team(
team_name=team_name, # Should be unique
team_members=[name],
team_description="test", # Optional
)
else:
sgc.LabTeam.LabTeamMember().insert1(
{"team_name": team_name, "lab_member_name": name}, skip_duplicates=True
)
sgc.LabMember.LabMemberInfo() & {
"team_name": "My Team",
"lab_member_name": "Firstname_spikesv0 Lastname_spikesv0",
}
| lab_member_name | google_user_name For permission to curate | datajoint_user_name For permission to delete | admin Ignore permission checks |
|---|---|---|---|
| FirstName LastName | gmail@gmail.com | user | 0 |
Total: 1
We can try fetch to confirm.
Exercise: Try to write a fer lines to generate a dictionary with team names as
keys and lists of members as values. It may be helpful to add more data with the
code above and use fetch(as_dict=True).
my_team_members = (
(sgc.LabTeam.LabTeamMember & {"team_name": "My Team"})
.fetch("lab_member_name")
.tolist()
)
if name in my_team_members:
print("You made it in!")
You made it in!
Code hidden here
members = sgc.LabTeam.LabTeamMember.fetch(as_dict=True)
teams_dict = {member["team_name"]: [] for member in members}
for member in members:
teams_dict[member["team_name"]].append(member["lab_member_name"])
print(teams_dict)
Adding an NWB file¶
Import Data¶
If you haven't already, load an NWB file. For more details on downloading and importing data, see this notebook.
import spyglass.data_import as sdi
sdi.insert_sessions("minirec20230622.nwb")
nwb_file_name = "minirec20230622_.nwb"
/home/sambray/Documents/spyglass/src/spyglass/data_import/insert_sessions.py:58: UserWarning: Cannot insert data from minirec20230622.nwb: minirec20230622_.nwb is already in Nwbfile table. warnings.warn(
Extracting the recording¶
SortGroup¶
Each NWB file will have multiple electrodes we can use for spike sorting. We
commonly use multiple electrodes in a SortGroup selected by what tetrode or
shank of a probe they were on.
Note: This will delete any existing entries. Answer 'yes' when prompted, or skip running this cell to leave data in place.
sgs.SortGroup().set_group_by_shank(nwb_file_name)
Each electrode has an electrode_id and is associated with an
electrode_group_name, which corresponds with a sort_group_id.
For example, data recorded from a 32 tetrode (128 channel) drive results in 128
unique electrode_id. This could result in 32 unique electrode_group_name and
32 unique sort_group_id.
sgs.SortGroup.SortGroupElectrode & {"nwb_file_name": nwb_file_name}
| nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | electrode_group_name electrode group name from NWBFile | electrode_id the unique number for this electrode |
|---|---|---|---|
| minirec20230622_.nwb | 0 | 0 | 0 |
| minirec20230622_.nwb | 0 | 0 | 1 |
| minirec20230622_.nwb | 0 | 0 | 2 |
| minirec20230622_.nwb | 0 | 0 | 3 |
| minirec20230622_.nwb | 1 | 1 | 4 |
| minirec20230622_.nwb | 1 | 1 | 5 |
| minirec20230622_.nwb | 1 | 1 | 6 |
| minirec20230622_.nwb | 1 | 1 | 7 |
| minirec20230622_.nwb | 10 | 10 | 40 |
| minirec20230622_.nwb | 10 | 10 | 41 |
| minirec20230622_.nwb | 10 | 10 | 42 |
| minirec20230622_.nwb | 10 | 10 | 43 |
...
Total: 128
IntervalList¶
Next, we make a decision about the time interval for our spike sorting using
IntervalList.
sgc.IntervalList & {"nwb_file_name": nwb_file_name}
| nwb_file_name name of the NWB file | interval_list_name descriptive name of this interval list | valid_times numpy array with start/end times for each interval | pipeline type of interval list (e.g. 'position', 'spikesorting_recording_v1') |
|---|---|---|---|
| minirec20230622_.nwb | 01_s1 | =BLOB= | |
| minirec20230622_.nwb | 01_s1_first9 | =BLOB= | |
| minirec20230622_.nwb | 01_s1_first9 lfp band 100Hz | =BLOB= | lfp band |
| minirec20230622_.nwb | 02_s2 | =BLOB= | |
| minirec20230622_.nwb | lfp_test_01_s1_first9_valid times | =BLOB= | lfp_v1 |
| minirec20230622_.nwb | lfp_test_01_s1_valid times | =BLOB= | lfp_v1 |
| minirec20230622_.nwb | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus | =BLOB= | spikesorting_recording_v0 |
| minirec20230622_.nwb | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times | =BLOB= | spikesorting_artifact_v0 |
| minirec20230622_.nwb | pos 0 valid times | =BLOB= | |
| minirec20230622_.nwb | pos 1 valid times | =BLOB= | |
| minirec20230622_.nwb | raw data valid times | =BLOB= |
Total: 11
Let's start with the first run interval (01_s1) and fetch corresponding valid_times. For the minirec example, this is relatively short.
interval_list_name = "01_s1"
interval_list = (
sgc.IntervalList
& {"nwb_file_name": nwb_file_name, "interval_list_name": interval_list_name}
).fetch1("valid_times")[0]
def print_interval_duration(interval_list: np.ndarray):
duration = np.round((interval_list[1] - interval_list[0]))
print(f"This interval list is {duration:g} seconds long")
print_interval_duration(interval_list)
This interval list is 10 seconds long
SortInterval¶
For longer recordings, Spyglass subsets this interval with SortInterval.
Below, we select the first n seconds of this interval.
n = 9
sort_interval_name = interval_list_name + f"_first{n}"
sort_interval = np.array([interval_list[0], interval_list[0] + n])
With the above, we can insert into SortInterval
sgs.SortInterval.insert1(
{
"nwb_file_name": nwb_file_name,
"sort_interval_name": sort_interval_name,
"sort_interval": sort_interval,
},
skip_duplicates=True,
)
And verify the entry
print_interval_duration(
(
sgs.SortInterval
& {
"nwb_file_name": nwb_file_name,
"sort_interval_name": sort_interval_name,
}
).fetch1("sort_interval")
)
This interval list is 9 seconds long
Preprocessing Parameters¶
SpikeSortingPreprocessingParameters contains the parameters used to filter the
recorded data in the spike band prior to sorting.
sgs.SpikeSortingPreprocessingParameters()
| preproc_params_name | preproc_params |
|---|---|
| default | =BLOB= |
| default_hippocampus | =BLOB= |
| default_min_seg | =BLOB= |
| franklab_default_hippocampus | =BLOB= |
| franklab_default_hippocampus_min_segment_length | =BLOB= |
| franklab_tetrode_hippocampus | =BLOB= |
| franklab_tetrode_hippocampus_min_seg | =BLOB= |
| lf_test | =BLOB= |
Total: 8
Here, we insert the default parameters and then fetch them.
sgs.SpikeSortingPreprocessingParameters().insert_default()
preproc_params = (
sgs.SpikeSortingPreprocessingParameters()
& {"preproc_params_name": "default"}
).fetch1("preproc_params")
print(preproc_params)
{'frequency_min': 300, 'frequency_max': 6000, 'margin_ms': 5, 'seed': 0}
Let's adjust the frequency_min to 600, the preference for hippocampal data,
and insert that into the table as a new set of parameters for hippocampal data.
preproc_params["frequency_min"] = 600
sgs.SpikeSortingPreprocessingParameters().insert1(
{
"preproc_params_name": "default_hippocampus",
"preproc_params": preproc_params,
},
skip_duplicates=True,
)
Processing a key¶
key is often used to describe an entry we want to move through the pipeline,
and keys are often managed as dictionaries. Here, we'll manage the spike sort
recording key, ssr_key.
interval_list_name
'01_s1'
ssr_key = dict(
nwb_file_name=nwb_file_name,
sort_group_id=0, # See SortGroup
sort_interval_name=sort_interval_name, # First N seconds above
preproc_params_name="default_hippocampus", # See preproc_params
interval_list_name=interval_list_name,
team_name="My Team",
)
Recording Selection¶
We now insert this key SpikeSortingRecordingSelection table to specify what
time/tetrode/etc. of the recording we want to extract.
sgs.SpikeSortingRecordingSelection.insert1(ssr_key, skip_duplicates=True)
sgs.SpikeSortingRecordingSelection() & ssr_key
| nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | interval_list_name descriptive name of this interval list |
|---|---|---|---|---|---|
| minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | 01_s1 |
Total: 1
SpikeSortingRecording¶
And now we're ready to extract the recording! The
populate command
will automatically process data in Computed or Imported
table tiers.
If we only want to process certain entries, we can grab their primary key with
the .proj() command
and use a list of primary keys when calling populate.
ssr_pk = (sgs.SpikeSortingRecordingSelection & ssr_key).proj()
sgs.SpikeSortingRecording.populate([ssr_pk])
Now we can see our recording in the table. E x c i t i n g !
sgs.SpikeSortingRecording() & ssr_key
| nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | recording_path | sort_interval_list_name descriptive name of this interval list |
|---|---|---|---|---|---|---|
| minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | /stelmo/nwb/recording/minirec20230622_.nwb_01_s1_first9_0_default_hippocampus | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus |
Total: 1
Artifact Detection¶
ArtifactDetectionParameters establishes the parameters for removing artifacts
from the data. We may want to target artifact signal that is within the
frequency band of our filter (600Hz-6KHz), and thus will not get removed by
filtering.
For this demo, we'll use a parameter set to skip this step.
sgs.ArtifactDetectionParameters().insert_default()
artifact_key = (sgs.SpikeSortingRecording() & ssr_key).fetch1("KEY")
artifact_key["artifact_params_name"] = "none"
We then pair artifact detection parameters in ArtifactParameters with a
recording extracted through population of SpikeSortingRecording and insert
into ArtifactDetectionSelection.
sgs.ArtifactDetectionSelection().insert1(artifact_key, skip_duplicates=True)
sgs.ArtifactDetectionSelection() & artifact_key
| nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | artifact_params_name | custom_artifact_detection |
|---|---|---|---|---|---|---|
| minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | none | 0 |
Total: 1
Then, we can populate ArtifactDetection, which will find periods where there
are artifacts, as specified by the parameters.
sgs.ArtifactDetection.populate(artifact_key)
Populating ArtifactDetection also inserts an entry into ArtifactRemovedIntervalList, which stores the interval without detected artifacts.
sgs.ArtifactRemovedIntervalList() & artifact_key
| artifact_removed_interval_list_name | nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | artifact_params_name | artifact_removed_valid_times | artifact_times np array of artifact intervals |
|---|---|---|---|---|---|---|---|---|
| minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times | minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | none | =BLOB= | =BLOB= |
Total: 1
Spike sorting¶
SpikeSorterParameters¶
For our example, we will be using mountainsort4. There are already some default parameters in the SpikeSorterParameters table we'll fetch.
sgs.SpikeSorterParameters().insert_default()
# Let's look at the default params
sorter_name = "mountainsort4"
ms4_default_params = (
sgs.SpikeSorterParameters
& {"sorter": sorter_name, "sorter_params_name": "default"}
).fetch1()
print(ms4_default_params)
{'sorter': 'mountainsort4', 'sorter_params_name': 'default', 'sorter_params': {'detect_sign': -1, 'adjacency_radius': -1, 'freq_min': 300, 'freq_max': 6000, 'filter': True, 'whiten': True, 'num_workers': 1, 'clip_size': 50, 'detect_threshold': 3, 'detect_interval': 10}}
Now we can change these default parameters to line up more closely with our preferences.
sorter_params = {
**ms4_default_params["sorter_params"], # start with defaults
"detect_sign": -1, # downward going spikes (1 for upward, 0 for both)
"adjacency_radius": 100, # Sort electrodes together within 100 microns
"filter": False, # No filter, since we filter prior to starting sort
"freq_min": 0,
"freq_max": 0,
"whiten": False, # Turn whiten, since we whiten it prior to starting sort
"num_workers": 4, # same number as number of electrodes
"verbose": True,
"clip_size": np.int64(
1.33e-3 # same as # of samples for 1.33 ms based on the sampling rate
* (sgc.Raw & {"nwb_file_name": nwb_file_name}).fetch1("sampling_rate")
),
}
from pprint import pprint
pprint(sorter_params)
{'adjacency_radius': 100,
'clip_size': 39,
'detect_interval': 10,
'detect_sign': -1,
'detect_threshold': 3,
'filter': False,
'freq_max': 0,
'freq_min': 0,
'num_workers': 4,
'verbose': True,
'whiten': False}
We can give these sorter_params a sorter_params_name and insert into SpikeSorterParameters.
sorter_params_name = "hippocampus_tutorial"
sgs.SpikeSorterParameters.insert1(
{
"sorter": sorter_name,
"sorter_params_name": sorter_params_name,
"sorter_params": sorter_params,
},
skip_duplicates=True,
)
(
sgs.SpikeSorterParameters
& {"sorter": sorter_name, "sorter_params_name": sorter_params_name}
).fetch1()
{'sorter': 'mountainsort4',
'sorter_params_name': 'hippocampus_tutorial',
'sorter_params': {'detect_sign': -1,
'adjacency_radius': 100,
'freq_min': 0,
'freq_max': 0,
'filter': False,
'whiten': False,
'num_workers': 4,
'clip_size': 39,
'detect_threshold': 3,
'detect_interval': 10,
'verbose': True}}
SpikeSortingSelection¶
Gearing up to Spike Sort!
We now collect our various keys to insert into SpikeSortingSelection, which is specific to this recording and eventual sorting segment.
Note: the spike sorter parameters defined above are specific to
mountainsort4 and may not work for other sorters.
ss_key = dict(
**(sgs.ArtifactDetection & ssr_key).fetch1("KEY"),
**(sgs.ArtifactRemovedIntervalList() & ssr_key).fetch1("KEY"),
sorter=sorter_name,
sorter_params_name=sorter_params_name,
)
ss_key.pop("artifact_params_name")
ss_key
{'nwb_file_name': 'minirec20230622_.nwb',
'sort_group_id': 0,
'sort_interval_name': '01_s1_first9',
'preproc_params_name': 'default_hippocampus',
'team_name': 'My Team',
'artifact_removed_interval_list_name': 'minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times',
'sorter': 'mountainsort4',
'sorter_params_name': 'hippocampus_tutorial'}
sgs.SpikeSortingSelection.insert1(ss_key, skip_duplicates=True)
(sgs.SpikeSortingSelection & ss_key)
| nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | sorter | sorter_params_name | artifact_removed_interval_list_name | import_path optional path to previous curated sorting output |
|---|---|---|---|---|---|---|---|---|
| minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | mountainsort4 | hippocampus_tutorial | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times |
Total: 1
SpikeSorting¶
After adding to SpikeSortingSelection, we can simply populate SpikeSorting.
Note: This may take time with longer data sets. Be sure to pip install mountainsort4 if this is your first time spike sorting.
# [(sgs.SpikeSortingSelection & ss_key).proj()]
sgs.SpikeSorting.populate(ss_key)
[11:33:09][INFO] Spyglass: Running spike sorting on {'nwb_file_name': 'minirec20230622_.nwb', 'sort_group_id': 0, 'sort_interval_name': '01_s1_first9', 'preproc_params_name': 'default_hippocampus', 'team_name': 'My Team', 'sorter': 'mountainsort4', 'sorter_params_name': 'hippocampus_tutorial', 'artifact_removed_interval_list_name': 'minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times'}...
Mountainsort4 use the OLD spikeextractors mapped with NewToOldRecording Using temporary directory /stelmo/nwb/tmp/tmpo38gkza9 Using 4 workers. Using tempdir: /stelmo/nwb/tmp/tmpo38gkza9/tmp05afo_06 Num. workers = 4 Preparing /stelmo/nwb/tmp/tmpo38gkza9/tmp05afo_06/timeseries.hdf5... Preparing neighborhood sorters (M=3, N=269997)... Neighboorhood of channel 1 has 3 channels. Detecting events on channel 2 (phase1)... Elapsed time for detect on neighborhood: 0:00:00.035859 Num events detected on channel 2 (phase1): 334 Computing PCA features for channel 2 (phase1)... Clustering for channel 2 (phase1)... Found 1 clusters for channel 2 (phase1)... Computing templates for channel 2 (phase1)... Re-assigning events for channel 2 (phase1)... Neighboorhood of channel 2 has 3 channels. Detecting events on channel 3 (phase1)... Elapsed time for detect on neighborhood: 0:00:00.036157 Num events detected on channel 3 (phase1): 463 Computing PCA features for channel 3 (phase1)... Clustering for channel 3 (phase1)... Found 1 clusters for channel 3 (phase1)... Computing templates for channel 3 (phase1)... Re-assigning events for channel 3 (phase1)... Neighboorhood of channel 0 has 3 channels. Detecting events on channel 1 (phase1)... Elapsed time for detect on neighborhood: 0:00:00.033028 Num events detected on channel 1 (phase1): 341 Computing PCA features for channel 1 (phase1)... Clustering for channel 1 (phase1)... Found 2 clusters for channel 1 (phase1)... Computing templates for channel 1 (phase1)... Re-assigning events for channel 1 (phase1)... Neighboorhood of channel 1 has 3 channels. Computing PCA features for channel 2 (phase2)... No duplicate events found for channel 1 in phase2 Clustering for channel 2 (phase2)... Found 1 clusters for channel 2 (phase2)... Neighboorhood of channel 2 has 3 channels. Computing PCA features for channel 3 (phase2)... No duplicate events found for channel 2 in phase2 Clustering for channel 3 (phase2)... Found 1 clusters for channel 3 (phase2)... Neighboorhood of channel 0 has 3 channels. Computing PCA features for channel 1 (phase2)... No duplicate events found for channel 0 in phase2 Clustering for channel 1 (phase2)... Found 1 clusters for channel 1 (phase2)... Preparing output... Done with ms4alg.
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/spikeinterface/sorters/basesorter.py:234: ResourceWarning: unclosed file <_io.TextIOWrapper name='/stelmo/nwb/recording/minirec20230622_.nwb_01_s1_first9_0_default_hippocampus/traces_cached_seg0.raw' mode='r' encoding='UTF-8'> SorterClass._run_from_folder(sorter_output_folder, sorter_params, verbose) ResourceWarning: Enable tracemalloc to get the object allocation traceback [11:33:24][INFO] Spyglass: Saving sorting results...
Cleaning tempdir::::: /stelmo/nwb/tmp/tmpo38gkza9/tmp05afo_06 mountainsort4 run time 12.62s
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/spikeinterface/core/basesorting.py:212: UserWarning: The registered recording will not be persistent on disk, but only available in memory
warnings.warn("The registered recording will not be persistent on disk, but only available in memory")
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/autopopulate.py:292: ResourceWarning: unclosed file <_io.TextIOWrapper name='/stelmo/nwb/recording/minirec20230622_.nwb_01_s1_first9_0_default_hippocampus/traces_cached_seg0.raw' mode='r' encoding='UTF-8'>
make(dict(key), **(make_kwargs or {}))
ResourceWarning: Enable tracemalloc to get the object allocation traceback
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/tempfile.py:821: ResourceWarning: Implicitly cleaning up <TemporaryDirectory '/stelmo/nwb/tmp/tmpo38gkza9'>
_warnings.warn(warn_message, ResourceWarning)
Check to make sure the table populated¶
sgs.SpikeSorting() & ss_key
| nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | sorter | sorter_params_name | artifact_removed_interval_list_name | sorting_path | time_of_sort in Unix time, to the nearest second |
|---|---|---|---|---|---|---|---|---|---|
| minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | mountainsort4 | hippocampus_tutorial | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times | /stelmo/nwb/spikesorting/minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_d318c3f1_spikesorting | 1710873204 |
Total: 1
Automatic Curation¶
Spikesorting algorithms can sometimes identify noise or other undesired features as spiking units. Spyglass provides a curation pipeline to detect and label such features to exclude them from downstream analysis.
Initial Curation¶
The Curation table keeps track of rounds of spikesorting curations in the spikesorting v0 pipeline.
Before we begin, we first insert an initial curation entry with the spiking results.
for sorting_key in (sgs.SpikeSorting() & ss_key).fetch("KEY"):
# insert_curation will make an entry with a new curation_id regardless of whether it already exists
# to avoid this, we check if the curation already exists
if not (sgs.Curation() & sorting_key):
sgs.Curation.insert_curation(sorting_key)
sgs.Curation() & ss_key
| curation_id a number correponding to the index of this curation | nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | sorter | sorter_params_name | artifact_removed_interval_list_name | parent_curation_id | curation_labels a dictionary of labels for the units | merge_groups a list of merge groups for the units | quality_metrics a list of quality metrics for the units (if available) | description optional description for this curated sort | time_of_creation in Unix time, to the nearest second |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | mountainsort4 | hippocampus_tutorial | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times | -1 | =BLOB= | =BLOB= | =BLOB= | 1710873795 |
Total: 1
Waveform Extraction¶
Some metrics used for curating units are dependent on features of the spike waveform. We extract these for each unit's initial curation here
# Parameters used for waveform extraction from the recording
waveform_params_name = "default_whitened"
sgs.WaveformParameters().insert_default() # insert default parameter sets if not already in database
(
sgs.WaveformParameters() & {"waveform_params_name": waveform_params_name}
).fetch(as_dict=True)[0]
{'waveform_params_name': 'default_whitened',
'waveform_params': {'ms_before': 0.5,
'ms_after': 0.5,
'max_spikes_per_unit': 5000,
'n_jobs': 5,
'total_memory': '5G',
'whiten': True}}
# extract waveforms
curation_keys = [
{**k, "waveform_params_name": waveform_params_name}
for k in (sgs.Curation() & ss_key & {"curation_id": 0}).fetch("KEY")
]
sgs.WaveformSelection.insert(curation_keys, skip_duplicates=True)
sgs.Waveforms.populate(ss_key)
[11:48:56][INFO] Spyglass: Extracting waveforms...
extract waveforms memmap: 0%| | 0/1 [00:00<?, ?it/s]
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/multiprocessing/popen_fork.py:66: ResourceWarning: Unclosed socket <zmq.Socket(zmq.PUSH) at 0x7f76c8677d00>
self.pid = os.fork()
ResourceWarning: Enable tracemalloc to get the object allocation traceback
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/multiprocessing/popen_fork.py:66: ResourceWarning: Unclosed socket <zmq.Socket(zmq.PUSH) at 0x7f752b912d00>
self.pid = os.fork()
ResourceWarning: Enable tracemalloc to get the object allocation traceback
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/multiprocessing/popen_fork.py:66: ResourceWarning: Unclosed socket <zmq.Socket(zmq.PUSH) at 0x7f76c8677760>
self.pid = os.fork()
ResourceWarning: Enable tracemalloc to get the object allocation traceback
[11:48:57][INFO] Spyglass: Writing new NWB file minirec20230622_4ZZBN5G9DY.nwb
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/hdmf/build/objectmapper.py:260: DtypeConversionWarning: Spec 'Units/spike_times': Value with data type int64 is being converted to data type float64 as specified.
warnings.warn(full_warning_msg, DtypeConversionWarning)
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/hash.py:39: ResourceWarning: unclosed file <_io.BufferedReader name='/stelmo/nwb/analysis/minirec20230622/minirec20230622_4ZZBN5G9DY.nwb'>
return uuid_from_stream(Path(filepath).open("rb"), init_string=init_string)
ResourceWarning: Enable tracemalloc to get the object allocation traceback
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/external.py:276: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
if check_hash:
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/autopopulate.py:292: ResourceWarning: unclosed file <_io.TextIOWrapper name='/stelmo/nwb/recording/minirec20230622_.nwb_01_s1_first9_0_default_hippocampus/traces_cached_seg0.raw' mode='r' encoding='UTF-8'>
make(dict(key), **(make_kwargs or {}))
ResourceWarning: Enable tracemalloc to get the object allocation traceback
Quality Metrics¶
With these waveforms, we can calculate the metrics used to determine the quality of each unit.
# parameters which define what quality metrics are calculated and how
metric_params_name = "franklab_default3"
sgs.MetricParameters().insert_default() # insert default parameter sets if not already in database
(sgs.MetricParameters() & {"metric_params_name": metric_params_name}).fetch(
"metric_params"
)[0]
{'snr': {'peak_sign': 'neg',
'random_chunk_kwargs_dict': {'num_chunks_per_segment': 20,
'chunk_size': 10000,
'seed': 0}},
'isi_violation': {'isi_threshold_ms': 1.5, 'min_isi_ms': 0.0},
'nn_isolation': {'max_spikes': 1000,
'min_spikes': 10,
'n_neighbors': 5,
'n_components': 7,
'radius_um': 100,
'seed': 0},
'nn_noise_overlap': {'max_spikes': 1000,
'min_spikes': 10,
'n_neighbors': 5,
'n_components': 7,
'radius_um': 100,
'seed': 0},
'peak_channel': {'peak_sign': 'neg'},
'num_spikes': {}}
waveform_keys = [
{**k, "metric_params_name": metric_params_name}
for k in (sgs.Waveforms() & ss_key).fetch("KEY")
]
sgs.MetricSelection.insert(waveform_keys, skip_duplicates=True)
sgs.QualityMetrics().populate(ss_key)
sgs.QualityMetrics() & ss_key
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/spikeinterface/postprocessing/template_tools.py:23: DeprecationWarning: The spikeinterface.postprocessing.template_tools is submodule is deprecated.Use spikeinterface.core.template_tools instead
_warn()
[12:17:37][INFO] Spyglass: Computed all metrics: {'snr': {1: 3.627503, 2: 3.598743, 3: 3.6419973}, 'isi_violation': {'1': 0.03896103896103896, '2': 0.036065573770491806, '3': 0.03488372093023256}, 'nn_isolation': {'1': 0.9591503267973855, '2': 0.9594771241830065, '3': 0.9872549019607844}, 'nn_noise_overlap': {'1': 0.49642857142857144, '2': 0.44738562091503264, '3': 0.4}, 'peak_channel': {1: 1, 2: 2, 3: 3}, 'num_spikes': {'1': 309, '2': 306, '3': 431}}
[12:17:37][INFO] Spyglass: Writing new NWB file minirec20230622_L3O536PHYB.nwb
[12:17:38][INFO] Spyglass: Adding metric snr : {1: 3.627503, 2: 3.598743, 3: 3.6419973}
[12:17:38][INFO] Spyglass: Adding metric isi_violation : {'1': 0.03896103896103896, '2': 0.036065573770491806, '3': 0.03488372093023256}
[12:17:38][INFO] Spyglass: Adding metric nn_isolation : {'1': 0.9591503267973855, '2': 0.9594771241830065, '3': 0.9872549019607844}
[12:17:38][INFO] Spyglass: Adding metric nn_noise_overlap : {'1': 0.49642857142857144, '2': 0.44738562091503264, '3': 0.4}
[12:17:38][INFO] Spyglass: Adding metric peak_channel : {1: 1, 2: 2, 3: 3}
[12:17:38][INFO] Spyglass: Adding metric num_spikes : {'1': 309, '2': 306, '3': 431}
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/hash.py:39: ResourceWarning: unclosed file <_io.BufferedReader name='/stelmo/nwb/analysis/minirec20230622/minirec20230622_L3O536PHYB.nwb'>
return uuid_from_stream(Path(filepath).open("rb"), init_string=init_string)
ResourceWarning: Enable tracemalloc to get the object allocation traceback
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/external.py:276: DeprecationWarning: The truth value of an empty array is ambiguous. Returning False, but in future this will result in an error. Use `array.size > 0` to check that an array is not empty.
if check_hash:
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/autopopulate.py:292: ResourceWarning: unclosed file <_io.TextIOWrapper name='/stelmo/nwb/recording/minirec20230622_.nwb_01_s1_first9_0_default_hippocampus/traces_cached_seg0.raw' mode='r' encoding='UTF-8'>
make(dict(key), **(make_kwargs or {}))
ResourceWarning: Enable tracemalloc to get the object allocation traceback
| curation_id a number correponding to the index of this curation | nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | sorter | sorter_params_name | artifact_removed_interval_list_name | waveform_params_name name of waveform extraction parameters | metric_params_name | quality_metrics_path | analysis_file_name name of the file | object_id Object ID for the metrics in NWB file |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | mountainsort4 | hippocampus_tutorial | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times | default_whitened | franklab_default3 | /stelmo/nwb/waveforms/minirec20230622_.nwb_0105557c_0_default_whitened_waveforms_qm.json | minirec20230622_L3O536PHYB.nwb | 4b1512bc-861f-4710-8fff-55aad7fbb6ba |
Total: 1
# Look at the quality metrics for the first curation
(sgs.QualityMetrics() & ss_key).fetch_nwb()[0]["object_id"]
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/hash.py:39: ResourceWarning: unclosed file <_io.BufferedReader name='/stelmo/nwb/analysis/minirec20230622/minirec20230622_L3O536PHYB.nwb'>
return uuid_from_stream(Path(filepath).open("rb"), init_string=init_string)
ResourceWarning: Enable tracemalloc to get the object allocation traceback
| snr | isi_violation | nn_isolation | nn_noise_overlap | peak_channel | num_spikes | |
|---|---|---|---|---|---|---|
| id | ||||||
| 1 | 3.627503 | 0.038961 | 0.959150 | 0.496429 | 1 | 309 |
| 2 | 3.598743 | 0.036066 | 0.959477 | 0.447386 | 2 | 306 |
| 3 | 3.641997 | 0.034884 | 0.987255 | 0.400000 | 3 | 431 |
Automatic Curation Labeling¶
With these metrics, we can assign labels to the sorted units using the AutomaticCuration table
# We can select our criteria for unit labeling here
auto_curation_params_name = "default"
sgs.AutomaticCurationParameters().insert_default()
(
sgs.AutomaticCurationParameters()
& {"auto_curation_params_name": auto_curation_params_name}
).fetch1()
{'auto_curation_params_name': 'default',
'merge_params': {},
'label_params': {'nn_noise_overlap': ['>', 0.1, ['noise', 'reject']]}}
# We can now apply the automatic curation criteria to the quality metrics
metric_keys = [
{**k, "auto_curation_params_name": auto_curation_params_name}
for k in (sgs.QualityMetrics() & ss_key).fetch("KEY")
]
sgs.AutomaticCurationSelection.insert(metric_keys, skip_duplicates=True)
# populating this table will make a new entry in the curation table
sgs.AutomaticCuration().populate(ss_key)
sgs.Curation() & ss_key
| curation_id a number correponding to the index of this curation | nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | sorter | sorter_params_name | artifact_removed_interval_list_name | parent_curation_id | curation_labels a dictionary of labels for the units | merge_groups a list of merge groups for the units | quality_metrics a list of quality metrics for the units (if available) | description optional description for this curated sort | time_of_creation in Unix time, to the nearest second |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | mountainsort4 | hippocampus_tutorial | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times | -1 | =BLOB= | =BLOB= | =BLOB= | 1710873795 | |
| 1 | minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | mountainsort4 | hippocampus_tutorial | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times | 0 | =BLOB= | =BLOB= | =BLOB= | auto curated | 1710876397 |
Total: 2
Insert desired curation into downstream and merge tables for future analysis¶
Now that we've performed auto-curation, we can insert the results of our chosen curation into
CuratedSpikeSorting (the final table of this pipeline), and the merge table SpikeSortingOutput.
Downstream analyses such as decoding will access the spiking data from there
# get the curation keys corresponding to the automatic curation
auto_curation_key_list = (sgs.AutomaticCuration() & ss_key).fetch(
"auto_curation_key"
)
# insert into CuratedSpikeSorting
for auto_key in auto_curation_key_list:
# get the full key information needed
curation_auto_key = (sgs.Curation() & auto_key).fetch1("KEY")
sgs.CuratedSpikeSortingSelection.insert1(
curation_auto_key, skip_duplicates=True
)
sgs.CuratedSpikeSorting.populate(ss_key)
# Add the curated spike sorting to the SpikeSortingOutput merge table
keys_for_merge_tables = (
sgs.CuratedSpikeSorting & auto_curation_key_list
).fetch("KEY")
SpikeSortingOutput.insert(
keys_for_merge_tables,
skip_duplicates=True,
part_name="CuratedSpikeSorting",
)
# Here's our result!
SpikeSortingOutput.CuratedSpikeSorting() & ss_key
| merge_id | curation_id a number correponding to the index of this curation | nwb_file_name name of the NWB file | sort_group_id identifier for a group of electrodes | sort_interval_name name for this interval | preproc_params_name | team_name | sorter | sorter_params_name | artifact_removed_interval_list_name |
|---|---|---|---|---|---|---|---|---|---|
| 662f3e35-c81e-546c-69c3-b3a2f5ed2776 | 1 | minirec20230622_.nwb | 0 | 01_s1_first9 | default_hippocampus | My Team | mountainsort4 | hippocampus_tutorial | minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_none_artifact_removed_valid_times |
Total: 1
Manual Curation with figurl¶
As of June 2021, members of the Frank Lab can use the sortingview web app for
manual curation. To make use of this, we need to populate the CurationFigurl table.
We begin by selecting a starting point from the curation entries. In this case we will use
the AutomaticCuration populated above as a starting point for manual curation, though you could also
start from the opriginal curation entry by selecting the proper key from the Curation table
Note: This step requires setting up your kachery sharing through the sharing notebook
starting_curations = (sgs.AutomaticCuration() & ss_key).fetch(
"auto_curation_key"
) # you could also select any key from the sgs.Curation table here
username = "username"
fig_url_repo = f"gh://LorenFrankLab/sorting-curations/main/{username}/" # settings for franklab members
sort_interval_name = interval_list_name
gh_url = (
fig_url_repo
+ str(nwb_file_name + "_" + sort_interval_name) # session id
+ "/{}" # tetrode using auto_id['sort_group_id']
+ "/curation.json"
) # url where the curation is stored
for auto_id in starting_curations:
auto_curation_out_key = dict(
**(sgs.Curation() & auto_id).fetch1("KEY"),
new_curation_uri=gh_url.format(str(auto_id["sort_group_id"])),
)
sgs.CurationFigurlSelection.insert1(
auto_curation_out_key, skip_duplicates=True
)
sgs.CurationFigurl.populate(auto_curation_out_key)
[16:04:49][INFO] Spyglass: Preparing spikesortingview data
Initial pass: segment 0 Segment 0 of 1 /stelmo/nwb/kachery-cloud/sha1/de/41/7a/de417af585eda5dc274c1389ad1b28ef1a0580ab
/home/sambray/mambaforge-pypy3/envs/spyglass/lib/python3.9/site-packages/datajoint/autopopulate.py:292: ResourceWarning: unclosed file <_io.TextIOWrapper name='/stelmo/nwb/recording/minirec20230622_.nwb_01_s1_first9_0_default_hippocampus/traces_cached_seg0.raw' mode='r' encoding='UTF-8'>
make(dict(key), **(make_kwargs or {}))
ResourceWarning: Enable tracemalloc to get the object allocation traceback
We can then access the url for the curation figurl like so:
print((sgs.CurationFigurl & ss_key).fetch("url")[0])
https://figurl.org/f?v=npm://@fi-sci/figurl-sortingview@12/dist&d=sha1://b0d9355ba302bcbcb7005822796fc850c06b6d3d&s={"initialSortingCuration":"sha1://2800ea072728fd141d8e5bc88525ac0c6c137d04","sortingCuration":"gh://LorenFrankLab/sorting-curations/main/sambray/minirec20230622_.nwb_01_s1/0/curation.json"}&label=minirec20230622_.nwb_01_s1_first9_0_default_hippocampus%20minirec20230622_.nwb_01_s1_first9_0_default_hippocampus_42be1215_spikesorting&zone=franklab.collaborators
This will take you to a workspace on the sortingview app. The workspace, which
you can think of as a list of recording and associated sorting objects, was
created at the end of spike sorting. On the workspace view, you will see a set
of recordings that have been added to the workspace.
Clicking on a recording then takes you to a page that gives you information about the recording as well as the associated sorting objects.
Click on a sorting to see the curation view. Try exploring the many visualization widgets.
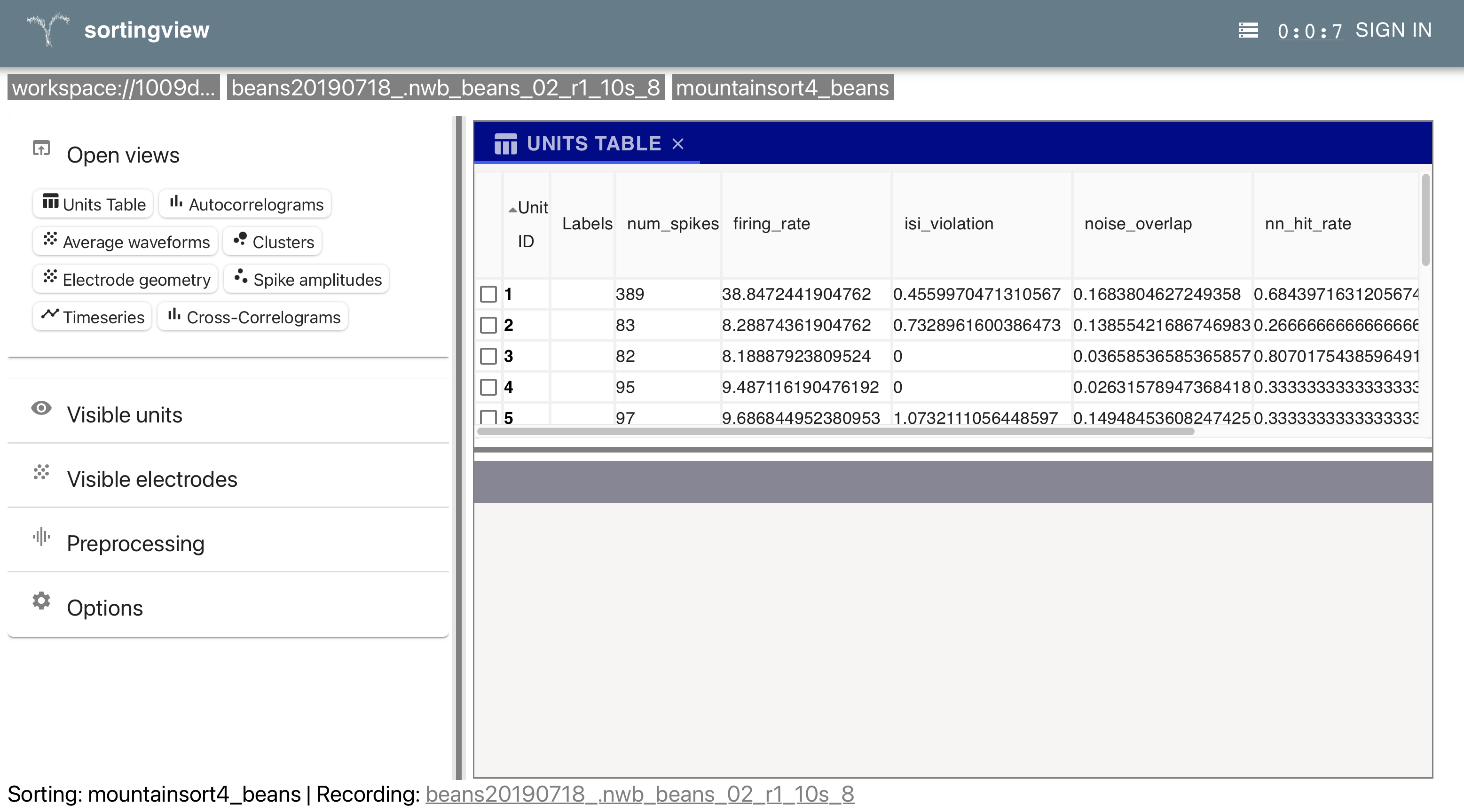
The most important is the Units Table and the Curation menu, which allows
you to give labels to the units. The curation labels will persist even if you
suddenly lose connection to the app; this is because the curation actions are
appended to the workspace as soon as they are created. Note that if you are not
logged in with your Google account, Curation menu may not be visible. Log in
and refresh the page to access this feature.